Re: svnmover feedback
Date: Fri, 1 May 2015 14:24:06 +0100
Daniel Shahaf wrote:
> Julian Foad wrote on Thu, Apr 30, 2015 at 10:30:39 +0100:
>> Usually, in practice, many elements are branched together, and this is
>> reflected in the model. Unlike copying, a branch contains a *set* of
>> elements. New elements can be added to the set later: this happens,
>> for example, when we merge the changes into this branch from a source
>> branch in which new elements have been created. Elements removed from
>> the branch can be re-added later as the same element ("resurrection").
>
> Okay, so an element is a node (in the svn_node_kind_t sense), and
An element comes in these kinds, and also a subbranch-root is another
kind of element.
> a branch operation forks a set of elements. Is that set necessarily
> a subtree rooted by some node, or could I, say, create a branch that
> contains only the elements subversion/*/main.c and no others?¹
The lower layer of the model works with arbitrary sets of elements,
which need not be connected in a single hierarchy. The higher layer --
wherein we implement merging and so on -- currently assumes and
requires a single hierarchy.
> You mentioned in an earlier mail that a branch is conceptually "mounted"
> into the fspath space. Is it possible to mount a branch at more than
> one point? (If yes, we'd immediately have in-repository hard links.)
In principle this could be possible. I have not explored this.
>> This is a significant difference from the old model of 'copying' where
>> each element (each file and directory) gets an independent new id [1].
>> And it matters particularly when you have the ability to move elements
>> around in the tree -- you need a way to track which elements are
>> members of which branch.
>
> That's probably not what you meant, but what would 'svn mv ^/foo/iota
> ^/bar/kappa' do, when /foo and /bar are related branch roots?
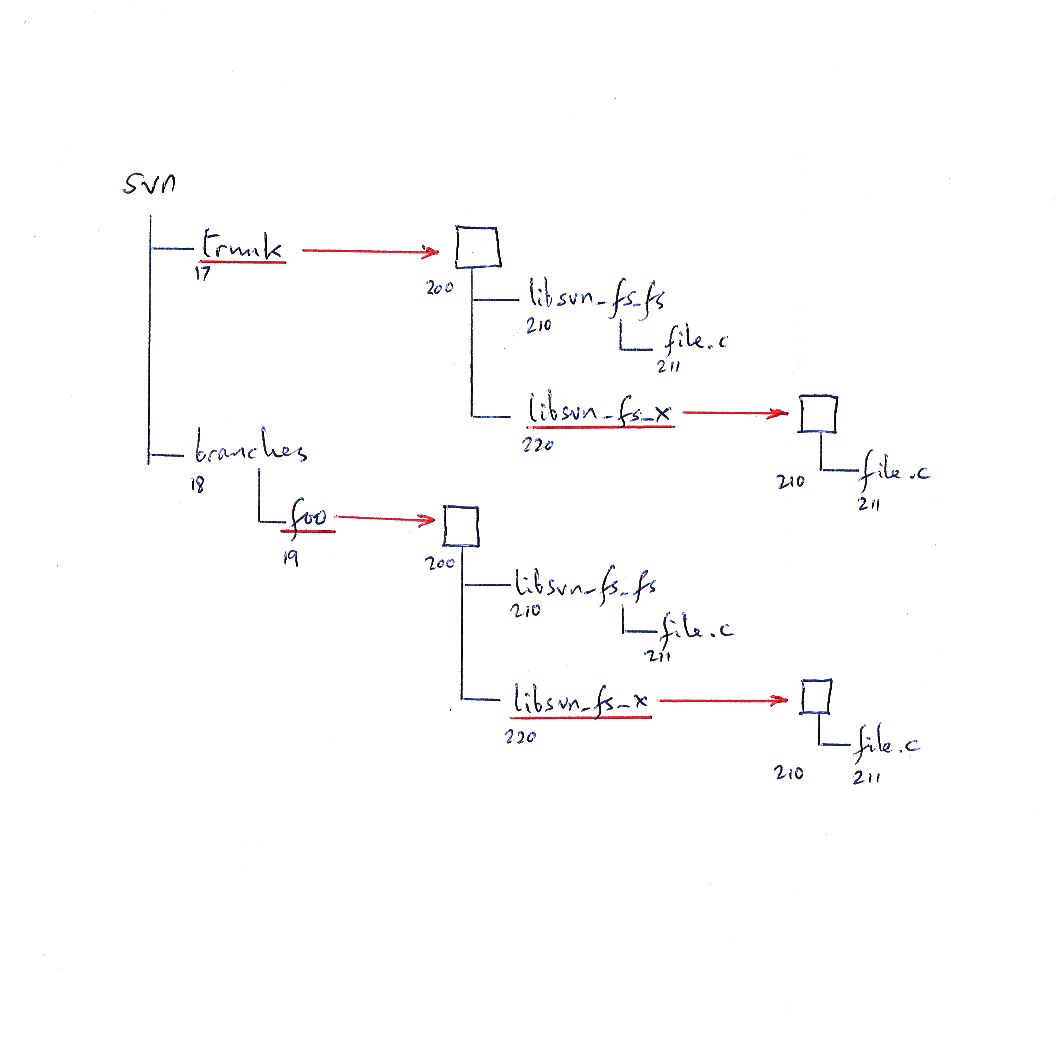
That's svnmover_tests.py 6: move to related branch.
'Moving something from one branch to another' means branching it (the
same as merging -r0:HEAD of it) to the target branch and un-merging it
(merging -rHEAD:0 of it) from the source branch.
Selected parts of the input and output of test 6 look like:
$ svnmover mv trunk/README branches/br1/README
mv: moving by branch-and-delete
V branches/br1/README (from trunk/README)
Committed r5:
--- diff branch B11 at /branches/br1
A e5 e1 /README
--- diff branch B2 at /trunk
D e5 e1 /README
Hmm, the notification "moving by branch-and-delete" suggests a
second-class kind of moving, by analogy with "copy-and-delete".
However, this definition is not arbitrary or second-class; it is
exactly what moving something from one branch to another *must* mean.
> And when
> /foo is a branch root and /bar is a path-wise-child of ^/ created by
> 'svn mkdir'?
Exactly the same, because the root branch (at path ^/) is a branch
like any other, related to other branches in the same way. (I got rid
of the notion of 'branch families' recently.)
$ svnmover mkbranch FOO mkdir FOO/iota mkdir BAR
A FOO (branch B25)
A FOO/iota
A BAR
Committed r16:
--- diff branch B0 at /
A e25 e0 /FOO (branch B...25)
A e27 e0 /BAR
--- added branch B25 at /FOO
$ svnmover mv FOO/iota BAR/kappa
mv: moving by branch-and-delete
V BAR/kappa (from FOO/iota)
Committed r17:
--- diff branch B0 at /
A e26 e27/kappa
--- diff branch B25 at /FOO
D e26 e24/iota
[...]
>> These new ids are independent for each file/dir: there is
>> no way to group them into sets.
>
> In the last sentence, "new ids" refers to the existing FS layers' copy
> ids in the example, not to the branch/element ids in the mv-t-2 branch,
> right?
Correct.
> Let me see if I understand. IIUC, in the new model, elements would know
> what branch they belong to,
An element is the union of all branches of the same file or directory
across all revisions. The metadata knows what *branches* each element
appears in, in each revision. Several branches may each contain an
instance of element e13. Element-instance B22:e13, or we could say
element-branch B22:e13, is the instance of e13 in B22.
> and would have unique ids that persist
> through renames within the branch and delete/resurrect cycles.
Yes.
> Element ids would be unique throughout the entire repository, right?
Yes (other than that the same element can appear once in each revision
in each branch).
> As an alternative, element ids could be made unique only throughout
> their branch and all branches that are copy-wise-descendants of the
> copy-wise-primogenitor of the branch that contains them — so, for
> example, /subversion/(trunk|branches/*) are one "element id space", but
> but /httpd/httpd/(trunk|branches/*) would be (together) another "element
> id space".
>
> After all, merging from httpd/trunk to subversion/trunk
> isn't defined; letting them have distinct element-id spaces would
> model that undefinedness. (I'm not sure how this compares with
> "branch families", which had been eradicated before I took a close look
> at the branch. Let me know if I just rehashed something that's been
> discussed already.)
Indeed, that was exactly the "branch families" model. Originally the
segregation seemed to be necessary in order to model subbranches, but
it is no longer necessary for anything. It is not necessary to have
segregated sets of EIDs in order to recognize that 'http' branches
have nothing in common with 'subversion' branches: the lack of any EID
appearing in both is sufficient.
Non-segregation is useful for certain scenarios such as if the user
decides to combine previously separate branch families into one
family. This is demonstrated in
svnmover_tests.py 11: restructure repo: projects/ttb to ttb/projects
If we want to model segregation of separate projects, this can be done
on top of the single-family model, whereas the reverse would not have
been possible.
>> Another significant property of a branch in this model is the
>> one-to-one correspondence between the (instances of) elements in this
>> branch and those in another branch, for the elements that appear in
>> both of the branches.
>
> I'm not sure I understand. Are you saying that element ids allow us to
> easily answer the question "What has element X on this branch been
> renamed to on that branch"? If so, then yes, it does, but how does it
> handles bifurcations [...]?
Bifurcation (splitting and joining) is deliberately not handled
specially -- only in the same way that it is now, by the user choosing
at most one 'tine' of the 'fork' to be the successor and the other(s)
to be plain copies. I decided modelling bifurcation explicitly at this
level would be too complex to justify for the relatively rare cases
where it could be useful.
The first level of complexity is reached as soon as you realize that
'splitting' is not a one-to-two relationship but a many-to-many
relationship (because you might split the same thing on two different
branches) and thus leads to a concept of groups of related elements,
and you have to choose what kind of relationship they should have --
perhaps a flat 'set' relationship, or a hierarchical relationship like
the tree formed by the existing 'copying' relationship. And then
justify why should it be different from what the 'copying'
relationship gives us.
In fact, the 'copy' relationship might be the *right* way to represent
splitting. Bear in mind that 'copying' will no longer be needed for
branching or merging-an-add or resurrection, as all of these are
handled explicitly by the new model.
[...]
> Tangentially related, should /@0 be a branch root?
Yes, it must. Element-instances can only exist in a branch, and it
would not make sense to have an exception where some elements can
exist but not in a branch.
> It seems like asking
> for trouble to allow one branch to be both a copy-wise-ancestor and
> path-wise-ancestor of another,
You mean branching where the target is *inside* the selected subtree
of the source branch, like 'svnmover branch . foobar'. At the
modelling level, it's necessary for self-consistency that it be
possible. The user interface might want to suggest it's usually not
what you want to do, I agree. I did indeed get into some 'trouble'
with recursion when first writing code around this, but it forced me
to re-evaluate and see the required code architecture more clearly, a
good result.
> and I don't see what use-case it serves
> other than users who accidentally created their contents in ^/ rather
> than in ^/trunk.
That's an intentionally served use case. The suggestion of requiring
people to have designated /trunk as a branch *before* creating any
contents in it was considered very bad for compatibility with
historical usage. This model has no such restriction.
> I assume making /@0 not-a-branch might mean nasty
> special-cases throughout the code, though… so perhaps make ^/ a branch
> that cannot itself be branched? i.e., have 'svnmover branch "" foobar'
> always fail regardless of the value of 'foobar'?
As I said, it's a UI concern. (Not to dismiss it, but to be clear that
it's not a good idea at the modelling level.)
[...]
Thanks for all the input. Do continue when able.
- Julian