Re: Let's discuss about unicode compositions for filenames!
Date: Fri, 3 Feb 2012 03:17:03 +0900
Everyone, read
http://svn.apache.org/repos/asf/subversion/trunk/notes/unicode-composition-for-filenames
again carefully before commenting to this thread, please!
2012/2/1 Peter Samuelson <peter_at_p12n.org>
>
>
> [reordering the conversation flow slightly]
>
> [Peter Samuelson]
> > > That's the implementation I would like to see, to be honest. Start
> > > with the observation that we can treat Mac OS X NFD paths as a
> > > client character encoding. Now observe that it is lossy. But
> > > ... almost all non-Unicode client charsets are equally lossy, for
> > > exactly the same reason!
>
> [Branko Cibej]
> > I don't see what you mean by "lossy" though. NFD and NFC can
> > represent exactly the same set of characters, it's just that the
> > representations of some of them are different.
>
> By "lossy" I just mean that if you convert to UTF-8 NFD, you can't
> reliably convert _back_ to the original bytes. I'm assuming here that
> we continue to do _no_ n11n on the server side - pathnames from
> libsvn_(ra|repos|fs) are just UTF-8 with unspecified n11n. Thus, if
> the "client encoding" is UTF-8 NFD, you can't reliably convert that to
> the "server encoding".
In option (2), we do n12n on all clients on all platforms, and we include
web_dav_svn in "clients". So we convert all input paths to the
"server encoding", which is NFC.
>
>
> And this is also true of most legacy (non-Unicode) encodings: they know
> nothing about Unicode's n11n forms, so they are "lossy" in the same
> way: you can't reliably take a pathname in, e.g., ISO-8859-1, and
> convert to the encoding found in the repository, because you don't know
> the n11n form used by the original committer.
>
> This is why I suggested the mapping table in wc.db.
>
> Actually, the fact that the mapping table works around the inherent
> lossiness of character encoding conversion suggests that it _could_, in
> the future, also account for lossiness for other reasons. If we
> wished, we could have libsvn_wc mangle checked-out filenames on
> platforms with arbitrary limitations - escaping "<" and ":" characters
> on Windows, e.g. - using this same mechanism. Even if the conversion
> is lossy, the mapping table in wc.db knows the original filename. Of
> course you couldn't _create_ filenames with platform limitations on the
> same platform, but being able to check out the file at all is an
> improvement over today. Probably 'svn status' would show some
> indication that a name has been mangled in a way users would actually
> care about (i.e., not just NFC/NFD).
"All problems in computer science can be solved by another level of
indirection."
Yes, with the mapping table, you can mangle filenames. However I think
it is too complex for novice users. Users must care about the original
filenames
and the mangled filenames all the time. Also you must adapt all clients to
use the mapping table. That is whole lot of work! Maybe you would
create another version control system.
>
>
> > > The implementation on OS X might be a bit hairy, if there isn't an
> > > easy way to retrieve the real pathname of the file you just
> > > created. Anywhere else, we just store the pathname we just
> > > calcuated.
>
> > Afaik the OSX API normalizes everything to NFD automagically. So at
> > least on that platform there's no chance of having more than one form
> > for the same filename at the same time. Likewise on Windows, which
> > normalizes to NFC.
>
> Right. The question is, if libsvn_wc tells OS X to store a given path,
> with unknown n11n, is there an easy way to retrieve the pathname that
> was _actually_ stored on disk? That's what I mean by "might be a bit
> hairy". It sounds like the thing to do on OS X is for libsvn_wc to
> pre-normalize to NFD before writing the file, and just assume the OS
> will (re-)normalize to the same byte array.
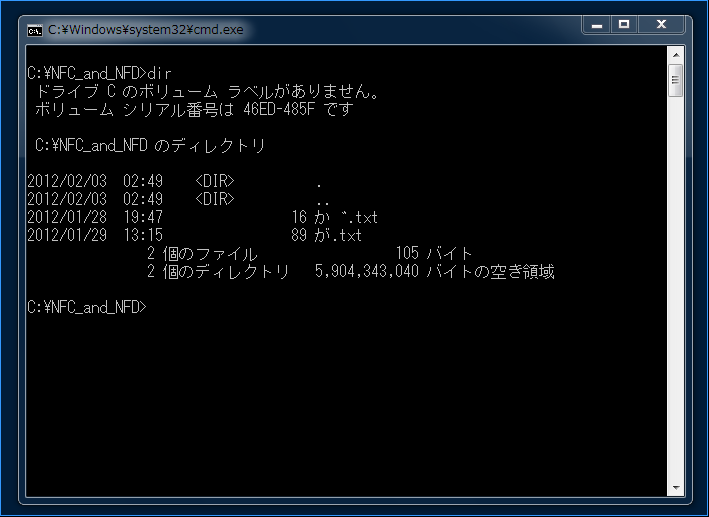
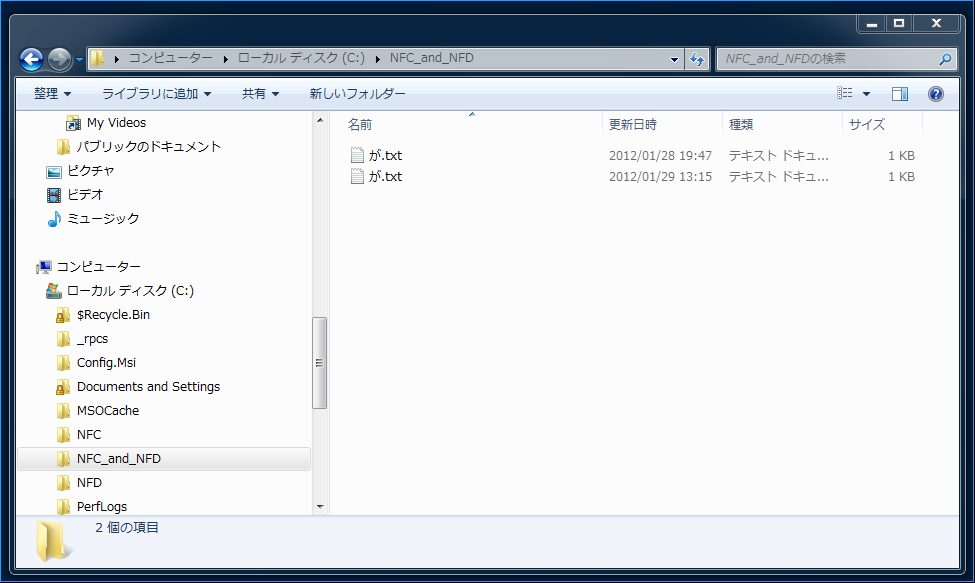
Wrong. Windows NTFS does not normalize filenames to NFC. See
the attached screenshots. We can have two "same abstract" filenames,
one NFC, one NFD in the same directory.
Explorer displays filenames in exactly the same form. Here is a quote
from Unicode Standard Annex #15, and Explorer conforms to the
last sentence.
http://unicode.org/reports/tr15/
> The Unicode Standard defines two equivalences between characters:
> canonical equivalence and compatibility equivalence. Canonical
> equivalence is a fundamental equivalency between characters or
> sequences of characters that represent the same abstract character,
> and when correctly displayed should always have the same visual
> appearance and behavior.
By contract, Command Prompts displays NFC filenames and NFD filenames
differently. However it should displays in the same way according to the
Unicode Annex above.
In the attached screenshot named
"NFC and NFD coexists on Command Prompt.png",
The first filename is NFD, the second file name is NFC.
NFC filenames looks familiar to me, and this is my first time to see
NFD filenames. It looks unnatural because one character are decomposed
and laid out separately, too much space between decomposed parts.
If novice users the situation like attached screenshots, they must be
very confused and upset. They would think "Oh why here we have the
two same filenames in one directory! It must be bug or something!"
So even if Windows NTFS can have the same abstract filenames in both
NFC and NFD simultaneously, we should avoid that, and we should only
allow NFC filenames.
So in a way OS X HSF+ is good, because it avoid the coexistence of
NFC and NFD filenames. It would be very happy for us if it choose NFC
instead of NFD!
-- )Hiroaki Nakamura) hnakamur_at_gmail.com