Hello Stefan.
Thak you very much for your comments. I'll respond to you next week.
I've been too busy with my studies. I'm studying your comments. I'd
like to discuss especially your idea about putting a foreign key to
the parent directory. What I do now is the following: if I get a
"deleted /foo/bar" I insert a row per subfile or subdirectory marking
them as deleted in that revision, and as you say this not linear, this
has a 1:N behaviour. I'll write a more concise mail next week.
This week I have had time to do some improvements:
* Now the code is threaded (one thread queries the repository while
other thread updates the cache).
* Zoom in-out
* colours showing the type of change (delete: red, modify: blue,
add/copy: green).
* tooltips showing date, author and comment
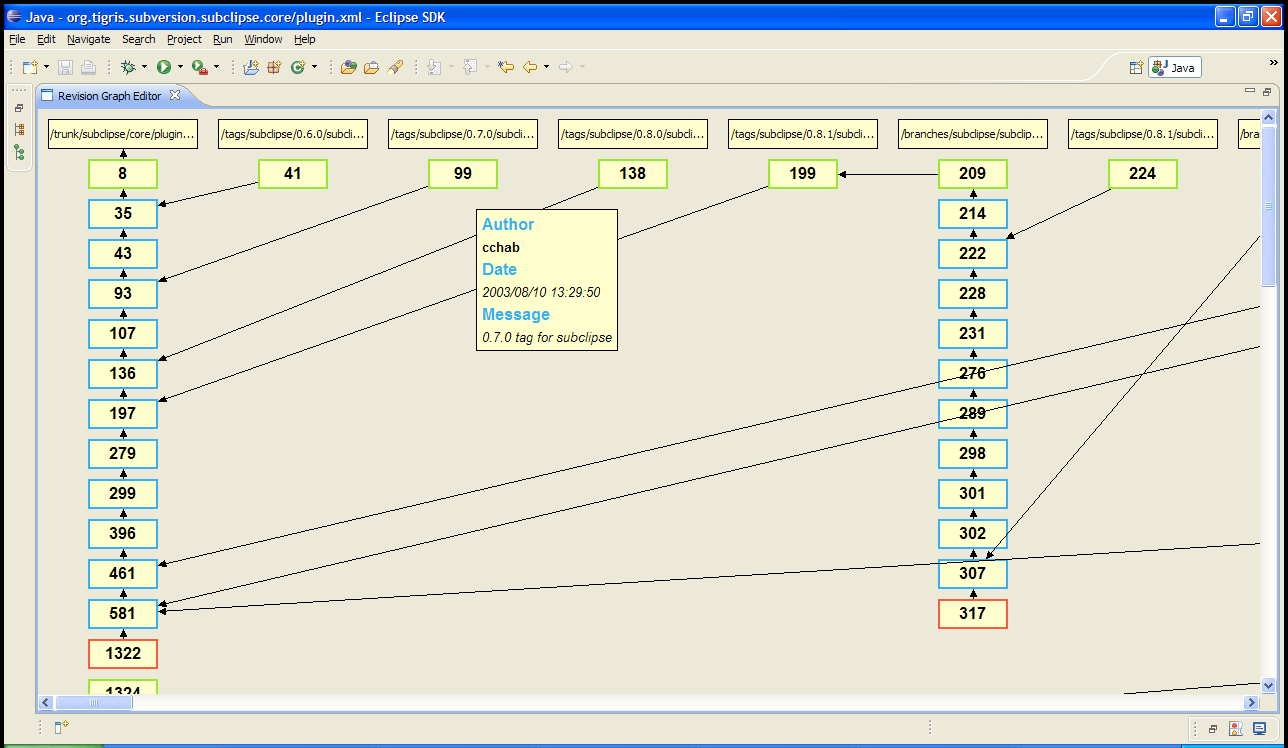
some shots:
http://farm4.static.flickr.com/3240/2658781686_a7a50e4e57_o.png
http://farm4.static.flickr.com/3062/2657955813_3a22ec4170_o.png (zoomed out)
The graph shown is the "plugin.xml" file from the subclipse core
plugin repository.
What I want to do now is:
* discuss the cache design
* put an option to hide the tags or show them in a different way
(maybe as an overlay icon)
* put an option to navigate to a certain branch (probably a combobox,
however I don't know how to do that yet)
* outlineview
* make it nicer :P
* make the background task cancellable. This should be not very
difficult now that I update the cache in several steps.
On Wed, Jul 9, 2008 at 4:16 PM, <Stefan.Fuhrmann_at_etas.com> wrote:
> On Tue, 8 Jul 2008 19:28:23 +0200, Alberto Gimeno <gimenete_at_gmail.com>
> wrote:
>
>> I also would like to know your opinions about the "possible
>> alternatives" I talked about in this post:
>> http://gimenetegsoc.wordpress.com/2008/07/01/the-cache-design/
>>
>> In that post I also talk about the cache general design.
>
> Hi Alberto,
>
> I think you are now ready for some constructive criticism ;)
>
> You just learned that efficient algorithms on large, attributed
> graphs are everything but simple. It's an active field of
> scientific research for a reason. Not that they are rocket
> science but those algorithms require careful planning and
> a deep understanding of the nature of the data they describe.
>
> Furthermore, using a RDMS to _process_ hierarchical data is
> a poor choice. But it is not a root of the problem. However,
> you still need some "data dump". And for that, a RDMS is as
> good a choice as any.
>
> That's for the criticism, now to the constructive part ;)
>
>
> Analysis:
> ---------
>
> As I understand it, you are storing for all files and folders
> the list of branches (plus revision ranges) that they are
> part of. Effectively, you pre-build most of the revision graph
> for every single node in the repository file system (minus
> those that are just copies of other nodes).
>
> Let N be the number of files in your project / component
> and R the number of revisions. Then there will be about R/B
> branches and tags with B being a project specific branching
> factor, e.g. "1 branch or tag every 100 revisions". Average
> folder depth is D is proportional to log N. Finally, C is
> the average number of changes per revision.
>
> For a medium-sized project this is N=1000, R=10000, B=100,
> C=10 and D=5. The problem is that a new branch (svn cp /trunk
> /branches/B) creates N new entries in your files table; total
> N*R/B = 100k entries. As R and N are roughly proportional,
> this results in quadratic dependency on the project "size".
> Ultimately, your cache update code will go berserk for larger
> projects.
>
> However, adding 1000 new entries every 100 revisions should
> take less than 1 second. *Finding* all copy sources can be
> an expensive operation if there is no index for the path
> string. E.g. you are looking for "/trunk" <= x < "/trunk\0x1".
>
> Another weak spot is the construction of the graph itself.
> To find the changes for a given file ID, you must read all
> its entries from the files table (approx. R/B entries).
> For every such entry, the list of *relevant* revisions has
> to fetched from the revisions and / or change_paths table.
> One possible solution is a (file_entry_id -> change_id)
> mapping table.
>
> Building this table is expensive: there is at least one
> entry per file_table_id (it's "ADD" revision) plus there
> is one entry per change of *any* sub-path. That's R*C*D
> (500k) entries or about 600k total. What makes things worse
> is that a naive implementation will walk up the path for
> every single change and tries to find the corresponding
> file_entry_id. That's C*D queries per revision!
>
> BTW, how do you handle copy-from info?
>
>
> Solution(s):
> ------------
>
> What you need to optimize for is to find all relevant data
> to draw a *single* revision graph. That is, fetch the data
> from the repository and transform it into some easy-to-access
> representation but do *not* add significant redundancy.
>
> Your idea of having file IDs is in line with SVN issue 1525.
> Keep it. If merge-tacking info gets added sometimes later,
> this abstraction will be very helpful.
>
> Modify the files table: add a column that links to the
> respective parent folder's entry. It is easy to see that this
> is possible and that the revision ranges do fully overlap.
> Add new entries only for those paths that are actually
> mentioned in the log changes. Hence, every copy adds only
> entry to the files table.
>
> To construct the list of all branches, aggregate the lists
> along the parent hierarchy. All parent-only entries in that
> list create a "branch" node and possibly a "deleted" node
> in the graph. All required information in already in the
> file list and no further look-up in the changes list is necessary.
>
> If that is not what you are already doing: Replace the paths
> in the changes table by references to the respective files
> table entry. For file nodes, this makes the retrieval trivial.
>
> Folder nodes are almost as simple to handle: Introduce a new
> table that represents the transitive inversion of the file
> path -> parent path column added to the files table. It also
> contains an entry for every file table row that points to
> the same row (i.e. is reflexive). The latter will also
> allow to run the same query for files and folders alike.
>
> So, it contains about D times more entries than the files table.
> For every path, all direct and indirect sub-paths that actually
> *do* have changes can be found efficiently. The changes table
> can then be JOINed directly.
>
> Based on the numbers collected by the TSVN log cache, you
> can expect the number entries in the files table to be 1/5th
> of the number of entries in the changes table. The new mapping
> table would be less than twice the number of entries than the
> changes table.
>
>
> While the result may still have its limitations, it should
> provide decent performance over a wide range of real-world
> projects.
>
> -- Stefan^2.
>
>
> ---------------------------------------------------------------------
> To unsubscribe, e-mail: dev-unsubscribe_at_subclipse.tigris.org
> For additional commands, e-mail: dev-help_at_subclipse.tigris.org
>
>
--
Alberto Gimeno Brieba
Presidente y fundador de
Ribe Software S.L.
http://www.ribesoftware.com
ribe_at_ribesoftware.com
Contacto personal
eMail: gimenete_at_gmail.com
GTalk: gimenete_at_gmail.com
msn: gimenete_at_hotmail.com
página web: http://gimenete.net
teléfono móvil: +34 625 24 64 81
---------------------------------------------------------------------
To unsubscribe, e-mail: dev-unsubscribe_at_subclipse.tigris.org
For additional commands, e-mail: dev-help_at_subclipse.tigris.org
Received on 2008-07-11 16:56:48 CEST
{kind=link}
{kind=link}